Historicamente, a indústria de tecnologia tem buscado formas eficientes para armazenar e analisar grandes volumes de dados. As soluções de armazenamento precisam lidar com o volume, latência, resiliência e variedade de requisitos de acesso aos dados demandados pelas organizações. Para lidar com estes desafios, as empresas utilizam uma pilha de tecnologias para data lakes se comportarem como um data warehouse ou data warehouses agirem como data lakes, processando e armazenando grandes volumes de dados. Ambas abordagens estão deixando os clientes insatisfeitos, gerando um alto custo de construção e manutenção das soluções.
Algumas empresas têm implementado arquiteturas separadas, onde os data warehouses ficam responsáveis pelos dados estruturados (ex. planilhas, CSV e tabelas de bancos de dados) e os data lakes armazenam grandes volumes de dados não estruturados (ex. imagens, vídeos e documentos) e semi-estruturados (ex. JSON e XML). Esta abordagem geralmente resulta em pipelines de ETL complexos devido a grande movimentação, processamento e duplicação dos dados. Operacionalizar e fazer a governança desta arquitetura de dados também se torna um desafio devido ao custo e complexidade.
Para resolver estes desafios, uma nova arquitetura emergiu: o Data Lakehouse. Ela combina os principais benefícios dos data lakes e data warehouses, oferecendo um armazenamento de baixo custo acessível por vários motores de processamento de dados, como Apache Spark, e disponibilizando funcionalidades poderosas de gerenciamento e otimização.
O que é um Data Warehouse (DW)?
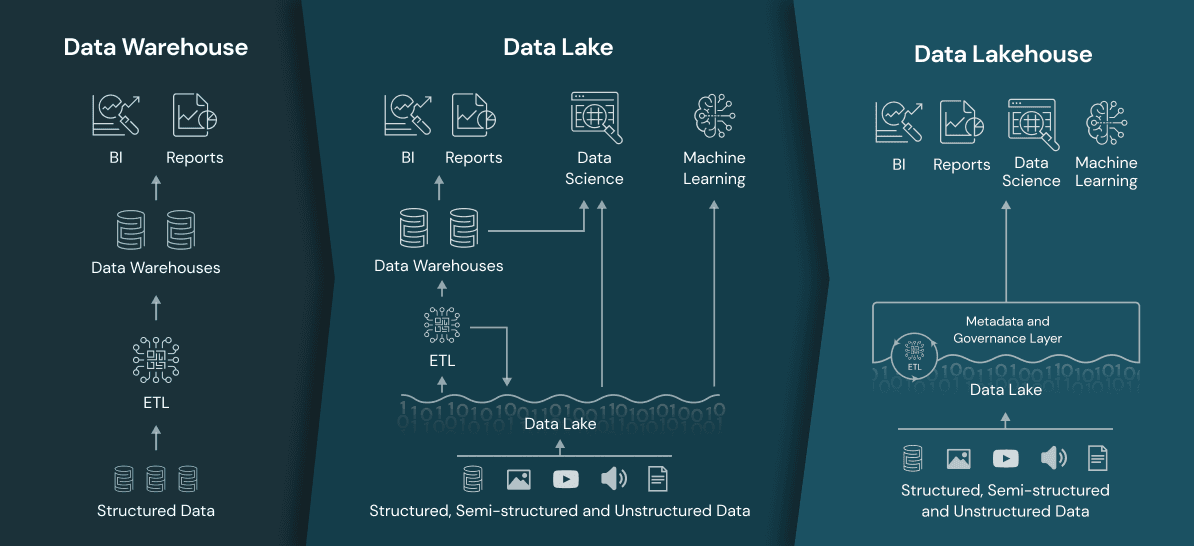
Um data warehouse é um armazenamento centralizado de informações que podem ser exploradas para tomar decisões mais adequadas. Os DWs destinam-se a realizar consultas e análises avançadas e geralmente contêm grandes quantidades de dados históricos. A principal motivação do surgimento dos DWs foi ajudar os líderes de negócio a realizarem análises sobre os dados estruturados (bancos de dados), para dar suporte a tomadas de decisão através de ferramentas de inteligência de negócio (BI). Um DW moderno (Figura 1) inclui:
- Um banco de dados que simplifica o gerenciamento dos dados e oferece maneiras diferentes de usá-los.
- Serviços de ingestão e transformação de dados para que os dados possam fluir de sistemas transacionais, bancos de dados relacionais e de outras fontes para o data warehouse, normalmente com uma cadência regular.
- Várias opções de análise que facilitam o uso de dados sem movê-los. Os DWs alimentam relatórios, painéis e ferramentas de análise armazenando dados de maneira eficiente para minimizar a entrada e saída (E/S) e fornecer resultados de consulta de forma mais rápida para um grande número de usuários simultaneamente.

Figura 1 — Arquitetura de um Data Warehouse (Fonte: Dremio)
O que é um Data Lake (DL)?
Para resolver estes desafios enfrentados no DW, foram desenvolvidas arquiteturas escaláveis de Data Lakes (DLs) com baixo custo de armazenamento dos dados brutos. O DL permite armazenar todos os tipos de dados, incluindo dados estruturados, semiestruturados e não estruturados. Em um data lake, os dados são transformados apenas quando são necessários para análises, por meio da aplicação de esquemas. Esse processo é denominado de “esquema na leitura”, já que os dados são mantidos no formato bruto até que estejam prontos para uso, sendo mais eficiente no armazenamento de qualquer tipo de dado.
Esta promessa que o data lake iria resolver todos os problemas do DW não foi cumprida em várias organizações. Isto ocorreu principalmente devido à dificuldade de desenvolvimento de soluções, gerenciamento do ambiente e produtização. Além disso, existe um grande desafio em garantir a qualidade, segurança e governança dos dados no data lake. Diante deste cenário, várias empresas criaram silos de dados que não eram facilmente compartilhados para os usuários de negócio. Isto impediu a democratização dos dados dentro das empresas.
Para mitigar este problema, durante os últimos anos, o data warehouse e o data lake tem co-existido de forma complementar (veja o exemplo na figura 2), sendo a arquitetura dominante na indústria atualmente. Nesta arquitetura, tradicionalmente os dados estruturados são armazenados no formato bruto no data lake, mas são processados e armazenados no formato tabular nos data warehouses. Os dados armazenados nos DWs são utilizados principalmente para análises de dados e inteligência de negócios (BIs). Já os dados semi-estruturados e não estruturados são armazenados no data lake e utilizados principalmente para Data Science e Machine Learning.
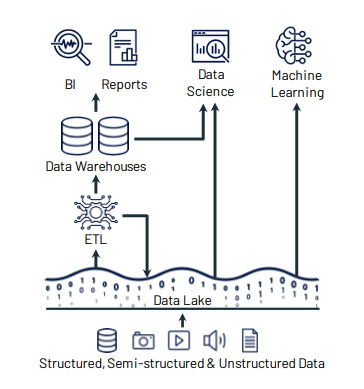
Figura 2 — Arquitetura de um Data Lake co-existindo com Data Warehouses (Fonte: Databricks)
Este modelo da figura 2 criou alguns problemas dentro das empresas:
- Os usuários de negócio que utilizam os DWs ficam limitados as análises possíveis de serem feitas com o DW, geralmente não conseguindo explorar os dados para um entendimento mais profundo deles;
- Os usuários do data lake ficam próximos dos dados brutos, mas têm que investir muito tempo na preparação dos dados do que realmente nas regras de negócio. Além disso, a exploração dos dados exige uma expertise em ferramentas de codificação para extrair valor das informações.
- Manter os dados consistentes entre o DL e o DW é uma tarefa difícil e cara.
- Os dados no DW ficam obsoletos em relação ao DL, já que existe uma frequência de atualização dos dados no DW que pode chegar a dias.
- As empresas pagam, pelo menos, o dobro do custo de armazenamento para manter a cópia dos dados no DL e no DW.
O que é um Data Lakehouse?
A arquitetura do Data Lakehouse tem como objetivo resolver estes desafios enfrentados no DW e DL para reduzir os custos operacionais, simplificar o processo de transformação e melhorar a governança. O lakehouse se tornou uma forma de centralizar e unificar as fontes de dados e esforços de engenharia na organização. Essencialmente, o uso do lakehouse permite que todos os usuários possam explorar os dados, independente de suas capacidades técnicas.
A ideia chave do Lakehouse é ter um sistema de armazenamento de dados de baixo custo no data lake, utilizando um formato aberto de arquivos, como Parquet e ORC. Estes formatos de arquivo são dados estruturados com esquema de dados (colunas e tipos das colunas) pré-definidos armazenados com os dados. Assim como no data lake, o lakehouse separa os recursos de processamento e armazenamento, ou seja, é possível que vários motores de processamento processem os mesmos dados sem ter que armazenar os dados de forma duplicada no data lake e no data warehouse.
Estes formatos abertos de arquivos mitigam o problema de trabalhar com dados estruturados no data lake. Mas, continua uma questão em aberto: como fornecer funcionalidades básicas dos DWs, como transações ACID, gerenciamento, versionamento, auditoria, indexação, cache e otimização de consultas utilizando estes formatos de arquivos? Se estes desafios não forem resolvidos, o lakehouse seria semelhante a um data lake.
Estes problemas são resolvidos utilizando uma camada de metadados transacional, como pode ser observado na figura 3, implementada sobre o sistema de armazenamento para definir quais objetos fazem parte de uma versão da tabela. Desta forma, é possível fornecer as funcionalidades dos DWs sobre os arquivos de formato aberto, como Parquet. Além disso, as soluções de lakehouse implementam outras otimizações para melhorar ainda mais o desempenho das consultas, como cache, estruturas de dados auxiliares (índices e estatísticas) e otimizações no layout do dado.

Figura 3 — Arquitetura da plataforma Lakehouse (Fonte: Databricks)
Como os lakehouses também separam o processamento de armazenamento, diferentes aplicações podem rodar sob demanda em um cluster separado (ex. cluster de GPU para Machine Learning), enquanto podem acessar diretamente os mesmos dados armazenados. Assim, é possível compartilhar recursos computacionais entre aplicações com overhead reduzido. Esta separação também permite definir orçamentos específicos em vários níveis e estágios. Por exemplo, você pode subir um cluster Hadoop na nuvem sob demanda, rodar jobs Spark sobre os dados do data lake e depois derrubar o cluster, pagando apenas pelo que usou de processamento. Assim não é preciso manter o cluster rodando 24×7, já que eles estão armazenados em um barramento de dados compartilhado no data lake.
O lakehouse possui componentes de ingestão, gerenciamento e análise dos dados que permite que diferentes ferramentas possam explorar estes dados para atender as necessidades dos usuários. As arquiteturas lakehouses se tornaram úteis tanto para aplicações de análise de dados e inteligência de negócio, quanto para ciência de dados e machine learning.
Comparação: Delta Lake, Apache Iceberg e Apache Hudi
Atualmente, as implementações open-source mais conhecidas e promissoras de lakehouse são: Delta Lake, Apache Iceberg e Apache Hudi. O Delta Lake, desenvolvido pela Databricks, é uma camada de armazenamento que traz transações ACID para o Apache Spark e workloads de Big Data. Apache Iceberg é um formato de tabela que permite múltiplas aplicações trabalharem no mesmo conjunto de dados de forma transacional e tem funcionalidades similares a tabelas em bancos de dados transacionais, de tal forma que múltiplos motores de processamento (Spark, Flink, etc.) possam operar no mesmo conjunto de dados. O Apache Hudi é uma solução mais focada em processamento de streaming de dados em uma camada de banco de dados auto-gerenciada. Além destas três opções, temos o Apache Hive ACID, que implementa transações utilizando o Hive Metastore para rastrear o estado de cada tabela. O Hive ACID tem sido mais utilizado em ambientes on-premise, principalmente quando em plataformas como a CDP da Cloudera.
O Apache Hudi é a solução mais robusta para construção de pipelines de streaming de dados. O Hive ACID pode ser uma boa escolha se você for adquirir a licença da plataforma CDP da Cloudera.
De forma geral, o Delta Lake possui a melhor integração com o ecossistema Spark (até porque a Databricks manda no Spark e no Delta Lake) e é uma solução mais madura no mercado. O maior problema do Delta Lake é que importantes otimizações só estão disponíveis na versão enterprise da solução. Em relação a maturidade, velocidade de desenvolvimento e documentação, mesmo na versão open-source, o Delta Lake sai na frente das outras opções. Existe muito material extremamente organizado no site da Databricks com vários exemplos para você desenvolver sua solução de dados.
O Iceberg tem uma solução menos madura que o Delta Lake, mas é totalmente open-source e possui várias otimizações importantes que não estão disponíveis no Delta Lake na versão open-source, por exemplo. Além disso, o Iceberg tem uma comunidade forte de contribuidores, incluindo grandes players do mercado como Netflix, Apple, Airbnb, Stripe, Expedia e Dremio. Em relação à versão open-source do Delta Lake, o Iceberg tem uma desvantagem na minha opinião que é o suporte a menos features na API Python em relação ao Java e Scala. Por exemplo, atualmente a API Python do Iceberg não tem suporte a escrita de dados. Mas, se você não tem nenhuma restrição em desenvolver os jobs em Java ou Scala, o Iceberg se torna uma boa opção devido as várias otimizações que serão importantes quando você colocar sua solução em produção. A documentação do Iceberg não é tão boa, mas não é nada que seja impeditivo para você construir sua plataforma de dados.
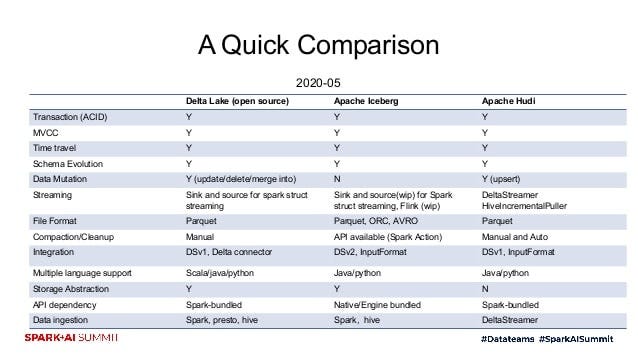
Figura 4 — Comparação entre o Delta Lake, Apache Iceberg e Apache Hudi (Fonte: Databricks)
Arquitetura Lakehouse na AWS
Os grandes players de Cloud Computing vêm montando sua arquitetura de Lakehouse utilizando as ferramentas já existentes na sua “nuvem” de opções. A arquitetura Lakehouse na AWS, apresentada na figura 5, é bem madura e está sendo desenvolvida há muitos anos para facilitar a vida dos engenheiros, analistas e cientistas de dados a entregarem valor mais rápido e confiável para os usuários.
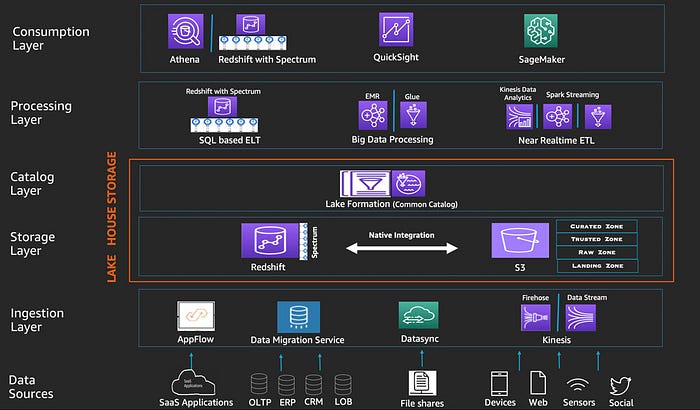
Figura 5 — Arquitetura Lakehouse na AWS (Fonte: Amazon)
A arquitetura lakehouse da AWS pode ser dividida em camadas para facilitar a compreensão:
Data ingestion layer: é composto por vários serviços de ingestão da AWS que entregam uma variedade de dados para o data lake e data warehouse. Cada serviço é indicado para uma fonte de dados: 1) bancos de dados (OLTP, ERP, CRM): AWS Data Migration Service, 2) aplicações SaaS: Amazon AppFlow, 3) arquivos (imagens, vídeos, etc.): AWS DataSync e 4) streaming de dados (logs, dados de sensores, redes sociais, etc.): Kinesis.
Storage Layer: é a camada chave da solução de lakehouse da AWS, unificando o Amazon Redshift e Amazon S3 nativamente. O Redshift é data warehouse que permite você armazenar os dados estruturados e semi-estruturados. O S3 é um serviço de armazenamento escalável de objetos, onde os dados estruturados, semi-estruturados e não estruturados podem ser armazenados. Você também pode armazenar seus dados estruturados no S3 utilizando os formatos padrões do Lakehouse, como Parquet e ORC. Desta forma, você irá conseguir utilizar múltiplos motores de processamento destes dados, como o Apache Spark. Os dados altamente estruturados no Redshift permitem que os usuários possam realizar consultas interativas e confiáveis, realizar análises sobre os dados e construir dashboards nos BIs de forma rápida e eficiente. Já o S3 é mais utilizado em casos de uso de processamento de big data, ciência de dados e aprendizado de máquina. O Amazon Redshift Spectrum é responsável pela integração do Redshift e o S3, permitindo que você consulte os dados de formato aberto (ex. Apache Parquet, ORC, JSON, Avro e CSV) no Redshift lendo diretamente do data lake do Amazon S3 sem precisar carregá-los nem duplicar sua infraestrutura.
Catalog Layer: o AWS Lake Formation fornece um catálogo central para armazenar os metadados para todos os datasets dentro do lakehouse (seja no S3 ou no Redshift). As organizações podem armazenar metadados técnicos (ex. esquemas versionados de tabelas) e atributos de negócios (ex. data owner e sensibilidade dos dados) no Lake Formation. Ele também fornece um lugar central para configurar permissões, usuários e grupos que podem ter acesso a tabelas e colunas. Esta camada está diretamente ligada a Storage Layer para permitir a construção de um lakehouse confiável e eficiente.
Processing Layer: esta camada fornece múltiplos componentes para permitir processar vários tipos de dados em diversos cenários de casos de uso. Cada componente pode ler e escrever diretamente do lakehouse, ou seja, do S3 ou Redshift. É possível construir jobs de processamento utilizando principalmente as seguintes ferramentas: 1) Amazon Redshift SQL (com Redshift Spectrum) para processamento de consultas SQL, 2) Amazon EMR ou AWS Glue para execução de jobs Spark em processamento big data e 3) Kinesis para ingestão de grandes volumes de dados com alta frequência ou streaming de dados (ex. dados de redes sociais ou sensores).
Consumption Layer: esta arquitetura lakehouse da AWS democratiza o consumo de dados por diferentes tipos de personas fornecendo serviços que permitem construir soluções em variados casos de uso, tais como: 1) consultas SQL interativas: os usuários podem utilizar o Redshift ou Athena para executar consultas SQL nos dados armazenados no Redshift ou nos dados estruturados armazenados no S3 (nos formatos abertos de arquivo como Parquet e ORC), 2) business intelligence: o Amazon QuickSigh pode ser utilizado para criar e publicar dashboards de BIs, consultando os dados no lakehouse com o Athena ou Redshift e 3) machine learning: os cientistas de dados podem utilizar o Amazon SageMaker para conectar na Storage Layer e explorar os dados para desenvolver, treinar e realizar o deploy de modelos de machine learning.
Assim, como a AWS vários outros provedores de serviços na nuvem, como Google Cloud e Microsoft Azure começaram a construir suas soluções integradas de arquiteturas lakehouse. O Google Cloud possui uma solução semelhante a da AWS para construção do lakehouse, mas usando o BigQuery e o Google Cloud Storage ao invés do Redshift e S3. A solução da Microsoft Azure é a plataforma da Databricks (que usa o Delta Lake), utilizando o Azure Data Lake Storage para armazenamento dos dados.
Considerações Finais
Uma arquitetura lakehouse irá permitir que você possa construir soluções para diversos cenários de uso e atender perfis variados de usuários de forma rápida, democratizando assim o acesso aos dados dentro da sua organização. Este post teve como objetivo descrever um pouco desta arquitetura e apresentar algumas opções para você implementá-la na sua empresa utilizando ferramentas open-source e/ou serviços na nuvem.